In recent years, deep learning technology has been frequently mentioned, reshaping the frontiers of computer vision and other artificial intelligence research fields. In robotics research, deep neural network (DNN)-based reinforcement learning enables robots to make autonomous decisions. With well-known games like Go, Warcraft, and StarCraft being used as research platforms, the application of robotic autonomous decision-making to human life is filled with imagination.
As an emerging robotics academic platform, the RoboMaster Competition Organizing Committee launched the RoboMaster AI Challenge. It invites enthusiasts worldwide to research DNN-based robotics technology, with the potential to apply the achievements to fields such as wilderness rescue, autonomous driving, and automated logistics, thereby benefiting human life. Jointly organized by the DJI RoboMaster Committee and the International Conference on Robotics and Automation (ICRA) since 2017, the competition has been held for five consecutive years, taking place in Singapore, Australia, Canada, and Xi'an, China. The event has attracted participation from numerous top universities and research institutions globally for both competition and academic discussions, further expanding RoboMaster's influence in the international robotics academic community. Participating teams are required to comprehensively apply knowledge in mechanical engineering, electronic control, and algorithms to independently develop fully autonomous shooting robots for the competition, demanding extremely high levels of comprehensive technical capability.
The organizing committee provides a standardized robot platform equipped with unified interfaces for projectile launching, attack detection, and other functions. Teams must independently develop algorithms, utilizing the onboard sensors and computing equipment to achieve autonomous robot decision-making, movement, and shooting. Participating teams are not permitted to use non-official robots. Teams need to prepare one or two robots to engage in fully autonomous shooting combat on a 5.1m x 8.1m (approximately 16.7 ft x 26.6 ft) competition field. During the match, robots identify and shoot projectiles at the opponent's armor modules to reduce their health points (HP). The team whose robots inflict higher total damage by the end of the match wins.
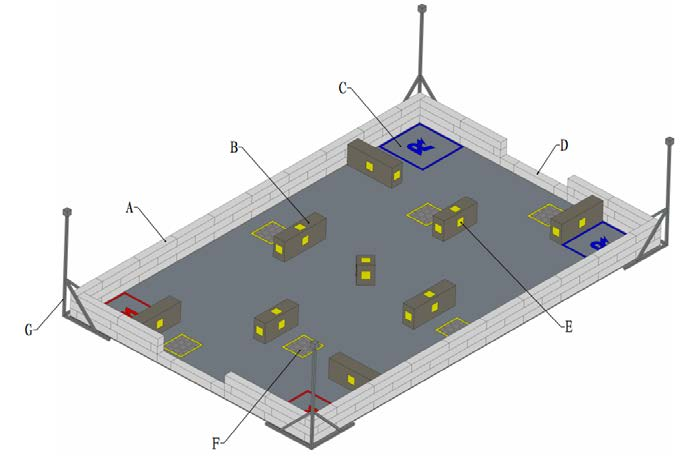
Battlefield
The core competition area is called the "Battlefield". The Battlefield is an area 8100 mm long and 5100 mm wide, primarily consisting of:Protective Barrier Zone (A),Obstacle Block Zone (B),Start Zone (C),Team Entrance/Exit Zone (D),Obstacle Block Marking Stickers (E),Buff/Debuff Zone (F),Sentry Posts (G).
Decision Making Module
During the competition, I served as the head of the decision-making group, responsible for the development of multi-robot decision-making algorithms. I did not take charge of the overall software and hardware framework design, etc. Therefore, this section will only introduce the decision-making design of the system. For the overall system design and other modules, please refer to the video in the DEMO section below.
Problem Formation
Under the rules of the DJI AI Challenge, we are addressing a multi-agent decision-making problem involving hybrid relational games in dynamic environments, characterized by partially observable environments, high real-time requirements, and continuous spaces.
To tackle this issue, we first abstract the inputs and outputs of the decision-making module. To reduce the decision space size and lower the difficulty and dimensionality of decisions, the outputs of the decision-making module are defined as the robot's target waypoints, shooting targets, and shooting commands. The motion of the chassis and gimbal is handled by the planning and shooting modules. Inputs include self information, ally information, enemy information, and environmental data. Furthermore, to enhance decision-making flexibility, we adopt a distributed architecture with homogeneous decision-making for algorithmic design.
The decision architecture is as follows:
Decision Architecture
Algorithm Design
Behavior Tree
Based on the behavior tree decision structure, we have designed a decision-making algorithm, including structural design, behavior definition, and condition design. The entire behavior tree is structured as follows: blue nodes represent condition nodes, yellow nodes represent control nodes, and the others are behavior nodes. The behaviors primarily include chase, interception, escape, go blood, go bullet, target select, etc. Details of specific node contents will not be elaborated here.
Behavior Tree
Reinforcement Learning
Based on the manually designed behavior tree approach, while it is easy to implement, offers stable performance, and possesses strong robustness, it also suffers from issues such as the optimality of behavior definitions and the rationality of condition definitions. To address the problems inherent in rule-based algorithms, we attempt to utilize a reinforcement learning (RL) framework, training for superior decision-making strategies based on a reward mechanism.
To circumvent challenges like training difficulties and non-convergence in RL, we draw inspiration from the structure of decision trees. Building upon manual behavior classification, we employ hierarchical reinforcement learning to separately train specific behaviors (corresponding to behavior nodes) and the selection of behaviors (corresponding to condition nodes).
Concretely, regarding the RL algorithms, we employ DQN (Deep Q-Network) and MADDPG (Multi-Agent Deep Deterministic Policy Gradient) to train behavior selection and specific behaviors respectively. The training process is phased: First, we conduct adversarial behavior training in groups based on MADDPG. Then, leveraging the trained individual behavior policies, we employ DQN to train unified behavior selection. Ultimately, a unified decision model is formed, consisting of one DQN network and multiple MADDPG Actor networks.
Reinforcement Learning Architecture
Demonstration
The video content below is from the technical report submitted by our team, HITCSC Team, in 2020.
HITCSC Team Technical Report
Achievements
Leveraging the team's long-term technical expertise and dedicated competition-focused R&D, our team achieved the following in the 2020 evaluations,including First Prize in Decision Group ,Second Prize in Perception Group and Third Prize in Navigation & Motion Planning Group announcement.Furthermore, in April 2021, we secured a top 8 position at the China Tournament in Xi'an, and that same June, claimed the Runner-up title at the Global Finals in Xi'an.announcement
First Prize of Decision Group
Acknowledgement
First and foremost, I would like to extend my heartfelt gratitude to our mentor, Prof. HE Fenghua, for providing us with the invaluable opportunity and platform to prepare for and participate in the highest-level cutting-edge robotics competitions.
Secondly, I sincerely thank our senior fellow students HAO Ning, YAO Haodi, XING Rui, LI Yuanhong, and ZHAO Qi,for their guidance and leadership throughout the competition. I also express deep appreciation to my teammates NIU Yinbao, LIN Zhaochen, ZHAO Mingwang, BAI Junming, WANG Hanbin and others for their dedicated efforts and hard work in the intense battles during the event.